

GPT-3 and A Typology of Hype

What's in this issue: Here, I try to deconstruct the buzz about GPT-3, and in trying to do that, I dig deeper into what hype means in the context of emergent technologies and how to integrate the noise out while consuming new science on social media. Read the rest of the post for a framework to think about the buzz in breakthrough technologies while living in the midst of it. GPT-3 or similar models did not assist in any of this writing. If you’re reading this over email, it might be best to read it directly on substack as some email clients clip long emails and block images used as illustration.
If you are a new visitor for the Page Street Labs newsletter, check out our hello world post explaining what this newsletter is about and why we exist.
GPT-3 and a Typology of Hype
Language is funny. Words have no “grounded” meanings unless you also take the full context of the reader and the writer, and yet we use words to get to that wordless essence with strangers we will never know. This was in full display when GPT-3 went viral, at least in Tech Twitter, over last weekend. Many researchers, including myself, used the words “GPT-3” and “hype” in the same Tweet to contain people's expectations. OpenAI's CEO, Sam Altman, even tweeted out “GPT-3 hype is way too much”.

But is GPT-3 a hype? There is definitely buzz about it on Twitter. Should buzz about something be the same as a hype? To examine these questions further, we need to first develop clarity around the word “hype” itself.
Background: The GPT in GPT-3 stands for Generative Pre-Training or Generative Pre-training Transformers depending on how you parse the earlier papers on the topic. In June 2018, Alec Radford and friends at OpenAI used a (then) novel combination of a generative deep learning architecture called the Transformer (from Google) and a technique for training with unlabeled data called unsupervised pre-training (also known as self-supervision). The resulting model is the GPT model.
The self-attention mechanism of the Transformer offers a general way to model parts of the input to depend on other parts of the input (with a lot of compute) without the model designer having to specify those relationships either by feature engineering or by architecture engineering. Somewhat precsiently, the authors of the original Transformer model titled their paper as “Attention Is All You Need”. The combination of Transformers and Unsupervised Pre-Training is not limited to GPT family of models. There’s a slew of language models (BERT, XLNet, T5 ..) from Google, Facebook, and various university labs releasing models using this combination. Hugging Face, a natural language processing company, maintains most publicly available transformer models in an easy to use open source software package.
By early 2019, OpenAI progressed their infrastructure to scale the same model with 10x the number of parameters and data. This was GPT-2. Later in 2019, we saw OpenAI introduce the SparseTransformer, an improvement over the earlier transformer models to reliably attend over longer documents. Finally, in 2020, OpenAI released GPT-3 via their beta API, which created the buzz in question. GPT-3 not only scales up the amount of data and compute used over GPT-2 but also replaces the vanilla Transformer with the SparseTransformer and other improvements to produce a model with the best zero-shot and few-shot learning performance to date. Few-shot learning refers to AI models/systems that can learn from a couple of examples. Zero-shot learning can do that with no training examples (think “fill in the blanks” kind of problems that rely on knowledge). Traditional ways to consume tranformer models use a technique called fine-tuning, where you adapt models for new scenarios by retraining on new labeled data. Beginning with GPT-2, OpenAI pushed few-shot and zero-shot learning as the primary way to consume transformer models, and it appears the promise has landed with GPT-3.
Couple important points to note: 1) Besides, OpenAI's SparseTransformer, there are consistent improvements in Transformer technology to speed up training, use fewer resources, and to improve attention over longer contexts. So one should expect the cost of this training (GPT-3 training budget is ~10-15 million USD) will go down significantly within the next year, 2) since GPT-3 is entirely trained on publicly available datasets the only moats to reproducing the work are budget and talent. Of these, the latter is the harder challenge but not unsurmountable by big AI research labs, like Baidu, Google, Facebook, Amazon, and some very select startups, and 3) The few-shot problem-solving capability of GPT-3 and other transformer models is not universal. While the model consistently impresses with few-shot learning for complicated tasks and patterns, it can fail, for example, on something as simple as learning to reverse a string even after seeing 10,000 examples.
The few-shot learning capabilities of GPT-3 lead to some very interesting demos, ranging from automatic code generation to “search engines” to writing assistance and creative fiction. Many of these applications are first-of-a-kind, and enable things that were not possible before, making the excitement and hype around GPT-3 understandable.
A Typology of Hype
The word hype implies something is amplified (often unjustly) and, therefore, the thing doesn't deserve as much attention. To say GPT-3 is a technology “hype” is to dismiss, what appears to be a qualitatively different model that's capable of solving complex problems that haven't been solved before (esp. in zero/few-shot settings) -- see Melanie Mitchell's analogy experiments or Yoav Goldberg's linguistic probing experiments. This is not to say folks are also not amplifying either cluelessly or irresponsibly with claims of sentience and general intelligence. Then there are folks downplaying it to folks being completely dismissive about it. To call GPT-3 a hype and, hence to not pay attention to it, is throwing the champagne with the cork. Many who worked on Machine Learning long before Deep Learning became formalized as a discipline, eagerly dismissed Deep Learning as “hype” in its early days and missed several exciting opportunities to contribute. Nothing better illustrates than this sentence, Eugene Charniak wrote in the preface to his Deep Learning book.

Prof. Charniak's humbling confession raises several questions: How does one distinguish real breakthrough technologies vs. pure manufactured social media shenanigans when faced with a buzzing topic? How does one not get too caught up with folks who downplay and fail to see something? How do we see-through potential inflations in the narratives of folks amplifying something? These are important questions to ask, especially with emerging technologies since, by definition, the wider community hasn't yet had a chance to dive deeper and codify the knowledge surrounding it.
Since AI moves faster than most computer science fields, and we want to operate and make decisions in the zone between the “innovation trigger” and “peak inflated expectation” of the Gartner hype cycle. We will have to rely on ways to look at hype other than frameworks outlined in, say, Christensen's Seeing What's Next and other classics. Further, none of the traditional management literature looks at early hype from a social media POV, where the hype creators have highly disparate incentives than the “market”.
To do this, I will argue in the rest of the post why it is important to see both the folks who are amplifying the topic and downplaying the topic to arrive a gestalt understanding without getting too influenced by the individual social media actors. Interestingly, the word “downplay” is not a good antonym for hype in the context of social networks where the default function is amplification, where even downplaying acts as a contributor to the overall buzz. For the sake of convenience, let's call hype as +hype and the opposite of hype as -hype. The term -hype can vary from casual hedging to downplaying to being dismissive to something downright vicious. Like how some Inuits purportedly have more than 50 words for snow, I feel it is essential to have different words for different kinds of +hype and -hype. Since I'm no Tolkien, instead of inventing new words, I will give you a 2x2 to explain the continuum of hype.

Before I dive into the 2x2 (higher-resolution image here), let me first point out some usual caveats:
The trouble of putting things in discrete categories can give an impression of those things being bounded and non-overlapping, but the reality is a complex entanglement. Since that's too hairy to examine, I use discrete categories like “folks who created it”, “futurism-types”, and so on. My naming of the categories can be iterated on and improved since naming is one of the hardest problems not only in Computer Science but elsewhere too.
The (X, Y) coordinates for various categories on the 2x2 are also approximate and, in some cases, reflect the bias of its creator. If you disagree with something, it useful to mentally rearrange those categories or have a discussion about it. I would love to hear that!
As with any 2x2, it's a thinking device and not a definitive map. So, in summary, there is nothing sacrosanct about this 2x2. Still, hopefully, the rest of the post will explain why this mental model can help us experience the texture of +hype and -hype around an emerging technology better.
To construct this 2x2, a useful axis to partition the hype continuum is the direct experience or knowledge of the person w.r.t the technology in question. Other possibilities exist, but since I am most interested in understanding the relative merits of the +hype and -hype direct experience/knowledge is a good discriminator.
At the edges of the 2x2 is the zone of engagement seekers. You have to watch out for people in these zones. They will co-opt any topic du jour and create content along the +hype and/or the -hype to drive engagement. They use “Wow!”, “SHOCKING!”, and other hyperbole to aid the spread of their message. Followers oblige. In the middle, around the low |hype|, there is a narrow band (in yellow), which is the zone of caution and indecisiveness. These folks don't talk much because either they choose not to as a policy or they are waiting for more information. These folks are not super useful either in concluding about the buzz topic. Then we have our four quadrants, A–D. Each quadrant is populated with a few examples of contributors to the overall buzz. As a mental model exercise, I will be going over each of the quadrants explaining what they are and apply it to breakdown the GPT-3 buzz and conclude as necessary.
A: (more direct experience/knowledge of the tech, +hype)
Folks who created it: This is understandable as the authors would want to spread awareness of their work. In many cases, such folks can overreach, but if they are researchers of repute, then it might be useful to pay attention to what they are saying closely and corroborate with other researchers in the field or do some lit search on your own. If it is not the authors, but the PR department of the company or universities, take all claims with a fist of salt. Interestingly, for GPT-3, unlike GPT-2, we saw very little direct comms from OpenAI. I think this is because OpenAI might have revamped their strategy to invite a bunch of trusted folks early in on the API access and let them build nifty video demos to become billboards for GPT-3. It's very clever and should be in the playbook of every company building creator tools/APIs.
Folks who see potential applications: These are inventor types. They are generally optimistic and come up with ten ideas on how to use anything you show them and are enthusiastic about sharing that. OpenAI harvested many of them either by design or by chance. I don't have data on this, but most of the early demo videos of GPT-3 apps I saw on Twitter came via Y-Combinator alums. Every demo video became a pitch deck for GPT-3. Tech Twitter lit up after this even though the official arXiv paper first came out by the end of May. While this is exciting "proof of work" that demonstrated what is possible, many of the videos are generated from cherry-picked content, so they appear more magical than it would if you were to use the API directly. If the results are cherry-picked, should we dismiss GPT-3's buzz? No. Perhaps the real magic of GPT-3, as it stands today, is GPT-3 with a human in the loop. There are numerous products in that category that's worth exploring with this model. Eventually, OpenAI released GPT-3 API to a bunch of NLP researchers (I have to apply yet), and we see interesting results come out of that already.
Aside: If you watched some of the demo videos and were floored about the capabilities of these new GPT-3 powered products, it is important to note that what you are watching is not the real-time performance and the results are lightly/heavily cherry-picked depending on the task. As a result, the videos can be more impressive/misleading than real-world experience (a general lesson for all video demos). That is not to say there is no signal in those videos. If anything, one should take the results in the videos as the upper bound of what's possible with current tech. We still have a long way to go to that upper bound. Max Woolf gave a good review of the system’s limitations of the current (July 2020) API that's worth reading.
Folks who think it will unblock their future work: These are the hopefuls. But it's usually tricky to tease them out unless you know them and their work very well.
Folks who “see the light”: These are folks who understand something deeper about the tech that others don't, despite not having a ton of evidence. Think of Hinton, (Yoshua) Bengio, LeCun, or Schmidhuber believing in shallow, deep networks way before the compute infrastructure existed. This crowd is usually a minority and are probably not adding much to visibility to the buzz, but they are important to listen to. The paradox is there are many undiscovered Hintons in the world right in the thick of the community. We have no one to blame but our biases.
B: (less direct experience/knowledge of the tech, +hype)
Angels and Investors: While some investors have direct experience in the tech they are investing in, many tend to rely on social proofs, pattern matching, and FOMO. For a sufficiently advanced tech like GPT-3 with very little background about it (other than a 70-page ArXiv paper), demos can be compelling to pattern match with other breakthrough technologies they've invested in. Unless they understand that demos are misleading, and there is a sufficient community exploration of the limits of the tech in question, investor hype is bound to happen. This doesn't mean there isn't a signal in the buzz the investor-type crowd is generating; it just means you need a substantial discounting factor there. Also, since these folks are relatively well connected in social media, the “buzz” we observe from their posts need to be normalized with their follower counts.
Aside: The excitement for investors is understandable since few-shot learning in GPT-3 provides the promise of no-code and low-code. Someone wrote GPT-3 is the next Bitcoin in terms of value creation. This is absurd. While GPT-3 certainly makes new possibilities available, I am going to bet with anyone willing that Stackoverflow will be alive and teeming with blood and flesh coders asking and answering help for low-level programming bugs for several years to come. If anything the investor excitement around GPT-3 reminds me of the early days of Deep Learning when mentioning DL on the pitch deck was a great fundraising strategy for the founder. Just like how Deep Learning will not help if you don't have a good business/product, it's very unlikely to create value out of thin air with a sprinkling of GPT-3, since the ease-of-use promise of such tech necessarily implies more competition and all other factors that separate winners from losers become more important than your ability to use GPT-3. Another perspective to consider is when Generative Adversarial Networks (GAN) and style transfer was in vogue and folks thought it will “replace artists” or at least flood the art market with computer-generated art. I won’t hold my breath for that to happen. Instead, GANs are slowly making significant progress in other areas less talked areas like data compression, speech synthesis, ...
First-time smitten: Some technologies enable certain folks to do something for the very first time. Imagine someone who has no idea how to write code and has never developed an app before, but now they see a path for them to develop something. That empowerment can feel exciting, and these folks substantially contributed to GPT-3 buzz. There is a useful signal here. While these folks are potential customers for future startups, they don't indicate much about the limits of the technology itself.
Velvet-rope winners: OpenAI's product launch strategy for GPT-3 was similar to Clubhouse, in effect, where folks wait in a metaphorical “velvet rope” to be admitted to the club. Practically everyone who got access to the API could not wait to post screenshots of the API in action even if they were posting text generation examples that were posted before 100 times, making it purely a signaling action. There is not much signal in the buzz added by this crowd.
Futurism types: These are folks who have been waiting for space pods and personal jetpacks. You can count on their excitement for any scientific progress. But their contribution to the buzz is not going to inform you much about the tech either.
C: (less direct experience/knowledge of the tech, -hype)
Cynics, Contrarians, and Negative Campaigns: Ignore them.
Mooks: These are folks who blindly retweet who they follow out of allegiance.
There is no signal in this quadrant, so you can step aside to quadrant D, which in my opinion, is quite interesting.
D: (more direct experience/knowledge of the tech, -hype)
False alarm survivors: These are folks who have gotten excited by similar promises in the past and have been let down. As a self-protection mechanism, their default response is to downplay the impact of the tech. This crowd is usually made of experienced folks who know what they are talking about, which makes it harder to ignore their opinions.
Shackled by your previous work: Sometimes folks fail to see what's new in a work like GPT-3 because they've been mentally imprisoned by the work they are doing or did in the past. It can come from a place of gross oversimplification — for example, someone comparing what GPT-3 is doing as “just another language model” — or failure to see the shift in the future as a discontinuity from the past. This is best illustrated by the ImageNet competition results. In 2012 the winning entry used a Deep Learning based approach and beat all other entries by a wide margin. Between 2012 and 2013, a lot of folks failed to see this “margin” as a shift as opposed to a linear extension of the current techniques. I was one of them, and I didn't course-correct until 2013-2014.

Something similar is happening with GPT-3, if not as dramatic. Zero-shot and few-shot learning are not new. But it appears like there is a qualitative (and definitely quantitative) difference between few-shot learning capabilities of GPT-3 and previous transformer models, including the GPT-2. Part of this could be because of the narrative that GPT-3 paper itself offers: “We use the same model and architecture as GPT-2 ...”

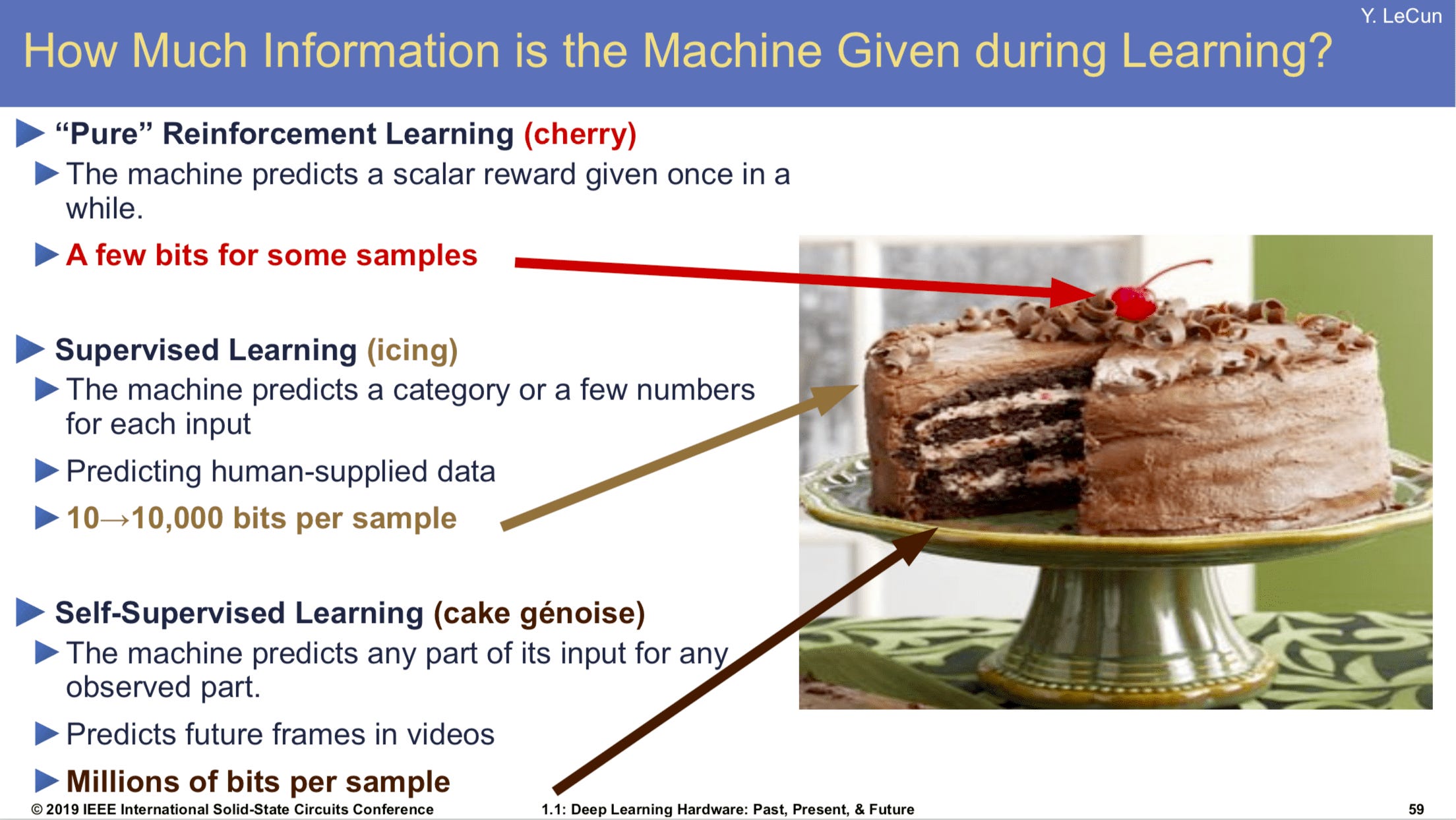
The opaqueness of the API is not helping external researchers in diving deep into GPT-3, but that could change because OpenAI might open up some of their models for more scrutiny than black-box level probing experiments or GPT-3 like models will get replicated elsewhere in open source. One thing is for sure: GPT-3 has unleashed the interest in few-shot and zero-shot learning beyond academic discussions, a trend that will only continue to strengthen in the future. A general trend that subsumes GPT-3 is self-supervision based representations. To use Yann LeCun's famous cake analogy, if supervised learning (what drove progress until 2018-2019) is the icing on the cake, self-supervision is the cake itself. Self-supervision will be changing all of Artificial Intelligence in the future.
Shackled by other constraints: Another source of -hype is from folks who think (rightly) that GPT-3 will not work for them today, either because it's slow or too expensive. While those are valid constraints for today, vesting our beliefs 100% in them will only restrict our freedom for innovating in the future since many of those constraints will be solved by progress in science. These buzz generated by such posts are not useful to assess the value of the technology.
Summary
GPT-3 and the buzz behind it is the beginning of the transition of few-shot learning technology from research to actionable products. But every breakthrough technology comes with a lot of social media buzz that can delude our thinking about the capabilities of such technologies. Examining the buzz closely as we’ve done here using mental models that are systematic can help expose some of our biases. No mental model is perfect, and all come with biases of their own, so using as many such models and having a conversation about them is essential. To further reduce bias, those conversations should be diverse, open, and inclusive.
Few-shot learning from GPT-3 like models can provide entirely new ways of building solutions. Given state of the art today, the sweet spot for leveraging few-shot learning is in situations that involve a human in the loop. It will be an overreach to confer an “autonomous” status to these models today, but it will be just as silly not to use them at all because the models make “errors”. Here’s a straightforward business idea: Use GPT-3 and humans-in-the-loop to build a data annotation business for training traditional low-resource supervised learning models. A human-in-the-loop model distillation!
GPT-3 marks the beginning of a Cambrian explosion of few-shot learning products, but that era will not be limited to or dominated by GPT-3 alone. We will see few-shot learning capabilities beyond the written text. Imagine the possibilities of doing few-shot learning from images, videos, speech, time-series, and multi-modal data. All this will happen in the early part of this decade, resulting in a proliferation of machine learning in more aspects of our lives. This proliferation will raise the urgency of working on like bias, fairness, explainability, and transparency of ML models. So will the importance of working on fighting adversarial applications of ML models.
If you like more such detailed analyses, do not forget to subscribe.
Disclosures: This article mentions multiple entities, including OpenAI. The author or Page Street Labs were not incentivized in any way to include them. They appear only because of the discussion I wanted to have. I have refrained from applying to the GPT-3 beta API until now, not to be obligated in any way by terms-of-use, etc.
Acknowledgments: Thanks to Jen-Hao Yeh for reading and commenting on early drafts of this.
Cite this:
@misc{clarity:gpt3-hype,
author = {Delip Rao},
title = {GPT-3 and a Typology of Hype},
howpublished = {\url{https://pagestlabs.substack.com/p/gpt-3-and-a-typology-of-hype}},
month = {July},
year = {2020}
}
The tips in your book have helped me become more productive! Before your article, I was wasting so much time figuring out what to do and how to spend my time on my projects. Thank you for your instructions on how to be organized and stay on schedule. I will be recommending your article often!
https://www.readerscook.site
In the vein of this analysis, would shifts in the relative size of each quadrant add information? Is it necessarily indicative of future performance if, say, the A quadrant (informed +hype folks) is larger by quantity than previous technology releases or hype cycles? Or may those fluctuations be a quirk of the tech itself or the culture?