How to Understand the Post-LLM Era
A mental model for builders and investors

✋ This post uses images, so if you are reading this on an email client, enable the “display images from sender” to get the most out of the post. If you are a new subscriber, welcome! If you find these writings valuable, consider sharing them with a colleague or giving a shoutout on Twitter. No generative tech was used in the writing of this article.
An investor recently invited a few builders and me for an informal dinner (thanks!). Over the conversation, it appeared what I assumed was common knowledge about LLMs wasn’t. I will share what I explained (with some supporting images).
This post is about how we interpret the business of software building in the world of large language models. We will do this by building a mathematical model of the world. But first, I want you to watch this infectiously exuberant clip.
EVERYTHING IN THE WORLD IS A FUNCTION. Functions have inputs and outputs. Functions come in all sorts of shapes (and shapes themselves are functions). You don’t have to be a mathematician or a computer scientist to understand this. Uber is a function (the app only exists to take your inputs in a way the function understands). Uber’s driver matching approximately looks like this.
Uber(user_id, lat, long) → driver_id
For a user (uniquely identified by user_id) and the user’s GPS coordinates (lat/long), it returns a driver (uniquely identified by driver_id) that will satisfy the user’s request. Once you develop this mental model, it’s impossible not to see functions everywhere.
DoorDash(user_id, lat, long, order_id) → delivery_id
Airbnb(user_id, property_id, start_date, end_date) → booking_id
LadyGAGA.com(city_id) → next_tour_date
BBCnews.com(location_id) → List[Headlines]
UnitedAirlines(user_id, source_id, destination_id) → ticket_id
. . .
If you stare at this list for a second, you will notice how the inputs, outputs, and exceptions to these functions are different. In other words, the SHAPES of these functions are different.
In the pre-LLM world, if we were to build a new concierge service that, say:
booked your concert ticket
rented an Airbnb at the concert destination
rented Ubers from/to the airports
Ordered pre-concert dinner and post-concert snacks
rented Ubers back and forth to the concert
This would involve a software engineering crew to understand the shapes of the functions that need to be called, and build and maintain pipelines to glue the output of one function as input to another function (function composition).
Functions of the world (manmade or natural) exist in different shapes because they evolved differently, and most innovations are made by the composition of functions (aka “higher-order functions”). In the pre-LLM world, making functions talk to each other (i.e., compose) would involve a human creating an app for every composition.
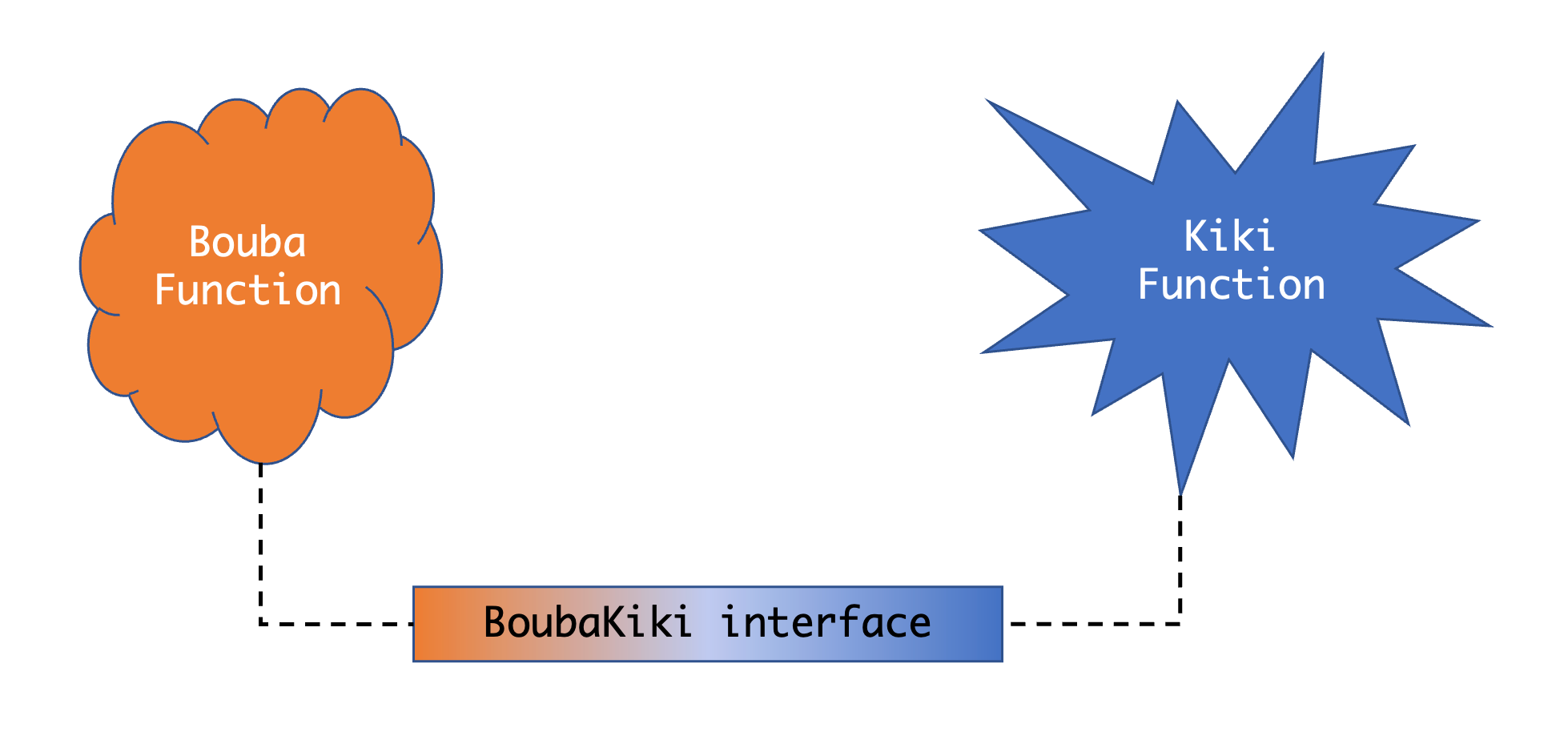
A close look at the App Store will tell us we have been quite industrious in building interfaces. Still, the process is tedious, and we have barely scratched the surface when realizing the exponential number of function compositions possible.
Large Language Models change all of that. Now imagine using simple descriptions (ChatGPT plugins or LangChain Tools), we have a natural language description of every function’s input and output. All of a sudden, we have different functions of the world speaking/understanding the same language:
Uber(request: string) → response: string
DoorDash(request: string) → response: string
Airbnb(request: string) → response: string
LadyGAGA.com(request: string) → response: string
BBCnews.com(request: string) → response: string
UnitedAirlines(request: string) → response: string
Now we have turned the Boubas and Kikis of the world into nicely conformal Lego™️ blocks that we can stack any way we want as long as we know what we are doing.
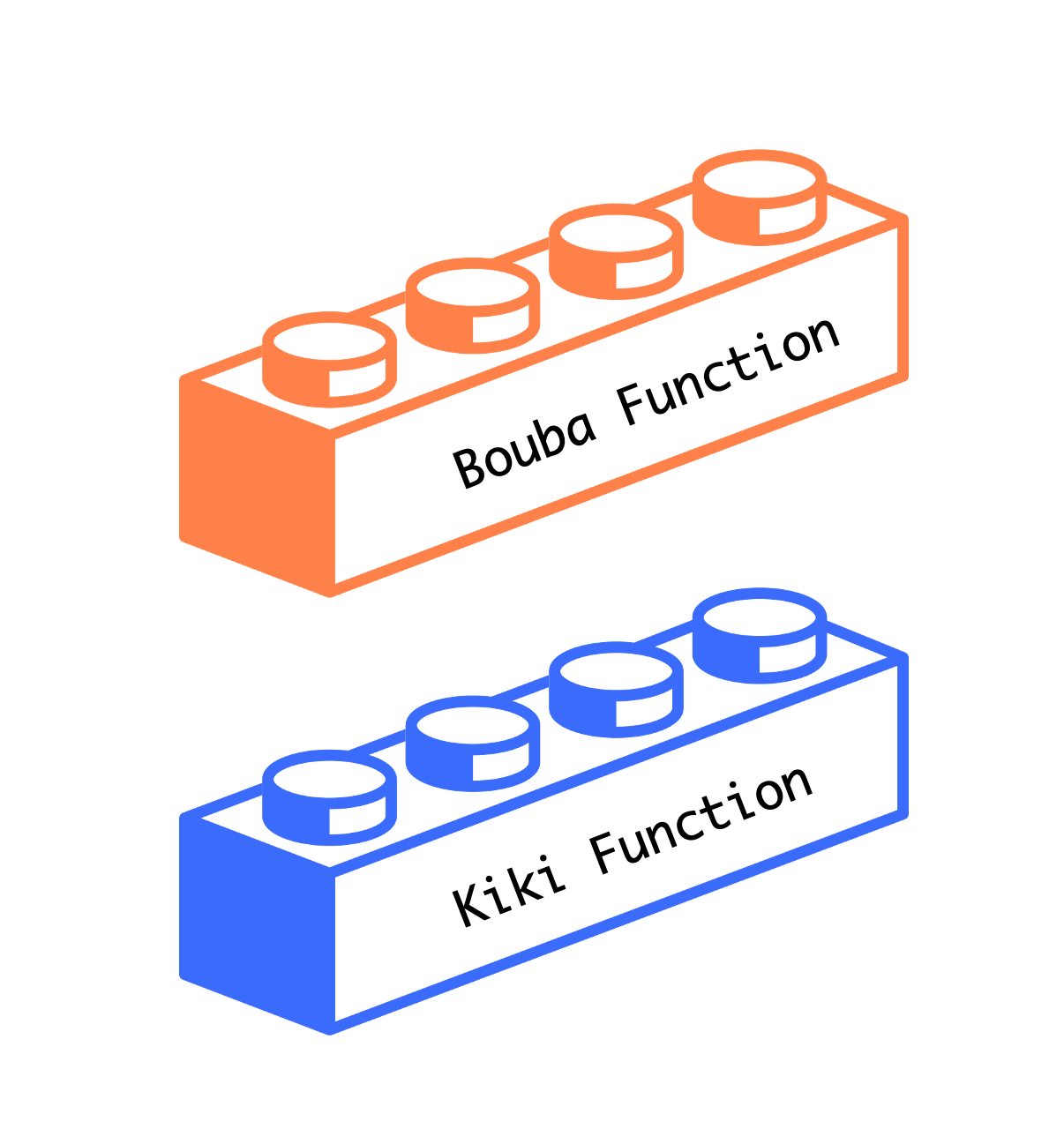
What are the (material) consequences of all this?
When was the last time everyone talked in the same language? To examine this, let’s go back to the 60s when three inventions changed the future of computing indelibly — the mouse (pioneered at Xerox PARC), UNIX (pioneered at AT&T Bell Labs), and ARPANET (precursor to the modern internet pioneered by DARPA).
Microsoft and Apple exploited the mouse to build point-and-click interfaces to bring computers to everyone.

But every program in it had to be built by either the vendor (Microsoft/Apple) or a third party, and it was difficult to make programs talk to each other.
In contrast, the command line was at the core of the UNIX design philosophy. Every program (optionally) took text input and (optionally) produced text output, chained together by the humble “pipe”. This allowed anyone to combine any two programs (“commands”), resulting in UNIX becoming the dominant computing platform.
The core philosophy of the UNIX command line is simplify-and-delegate — simplify the interfaces and delegate the complexities to the endpoint.
For our second example of when everyone talked the same language, consider ARPANET, the precursor of the current internet, developed in the late 60s. By the early 70s, Cerf & Khan, introduced the IP protocol and the layered architecture that’s all common now.
It would be extremely convenient if all the differences between networks could be economically resolved by suitable interfacing at the network boundaries. For many of the differences, this objective can be achieved. However, both economic and technical considerations lead us to prefer that the interface be as simple and reliable as possible and deal primarily with passing data between networks that use different packet switching strategies.
And convenient it was! Since its adoption and various revisions, the IP protocol got any and all devices to the internet, and any computer or device could talk to another because of the simplify-and-delegate paradigm adopted by Cerf & Khan.
What the IP protocol did for physical devices, modern LLMs are doing that for the application layer. For the first time, it is possible to make any application talk to any other application, assuming it makes sense for them to talk.
The question now is, do you treat LLMs as the Mouse or the UNIX pipe? The chat UX interface is misleading people into thinking it is the new Mouse. Except it isn’t. People hate typing unless they are forced to or have a strong incentive to do so. Speech-to-text is also not a vector because human speech is far slower than the reaction times offered by sight and motor neurons. My bet is LLM apps are the new UNIX pipes. Except for a few, the most winning LLM applications will be the silent grease running backend systems.
TLDR:
Prior to LLMs, the world operated with fixed schemas. LLMs allow us to provide schemaless APIs to things.
The schemalessness of the world will result in arbitrary mashups of applications possible by non-expert end users.
PS: We don’t fully know the consequences of the forth-coming Cambrian explosion of Apps, but I do know that this is along the gradient of progress, and progress cannot be stopped. Thoughtful solution-building and being open source, or at least being open to third-party introspection, is necessary.
Brilliant, simple and intuitive explanation. This is worthy of a being in a school curriculum. Gonna use this to explain to my kid. Thanks for sharing with the world
Functions! ITS ALL IT. YEET.
Great post, I agree with you. ChatGPT is an application built on this new way of building. I'm excited to see who keeps building like this (and not just plugging in GPT4).