

Ride the Hardware Lottery!
Issue #3: Why comparing models like GPT-3 with human brain/intelligence is flawed in a unique way.

This post heavily relies on illustrations, which are embedded images. If you’re reading this over email, it might be best to read it directly on substack as some email clients clip long emails and block images.
As you can tell from the previous two posts on Page Street Labs, I have been obsessed with Very Large Parameter (VLP) models lately. I wasn’t always this way. On my personal blog and Twitter feed, I have written enough about the culture of building models by stacking layers and praying it works. Ever since we figured out that adding more parameters (more layers specifically) helps, folks have been pushing that limit. Here’s an example from ImageNet:
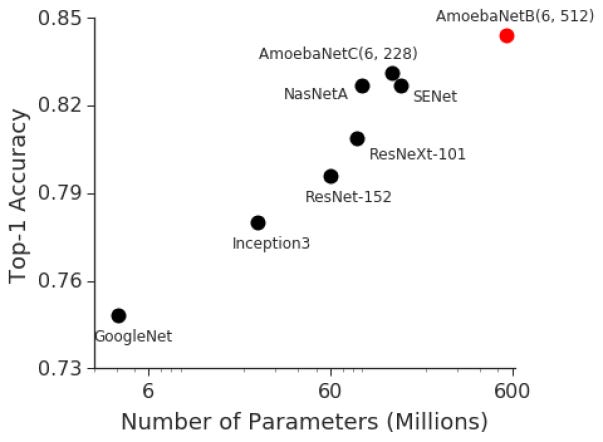
And most of those efforts are B-O-R-I-N-G (but with a side of good lessons that may not be widely applicable). However, something is fundamentally different about Very Large Parameter models (think GPT-3 scale and beyond) in terms of their capabilities.
The Hardware Lottery
Sara Hooker from Google published an essay on arXiv (btw, should this be on arXiv too? There’s a BibTeX entry at the end ... sempai cite me please?) explaining how certain areas of research get a lot of attention and win a lot of support — including software and hardware — over others that the article calls “The Hardware Lottery”, and how this discourages innovation investments in other areas. The hardware lottery is not new; not even in computer science, but the central plea of that essay is “Hardware Lotteries are holding us back and should be avoided.”
Hardware lotteries, and more generally, resource lotteries, have existed for as long as technology has, simply because of the nature of innovation and the economics of capital intensive enterprises. For example, sophisticated hydraulic engines were replaced by electrical counterparts over the decades, but until then a lot of interesting ideas and applications (e.g. Bessemer process and the mass production of steel) came out of hydraulic technology. Even with electrical actuators, the strength of the electrical field you can generate limits the pressure you can produce while hydraulics are only limited by the strength of materials. So, even if Electricity was a uniformly superior/efficient technology, there are no absolute winners; It all depends on the context. I can keep going, but this is not a post on the evolution of innovation (a favorite topic of mine so we will no doubt revisit that in a later post). This is a post about exploiting the inevitable hardware lotteries. To do that fully, we need to understand scaling of models before we write them off as wasteful exercises.
Not All Big Things Are Alike
Our intuitions about scaling are often flawed. Strange things happen at the extremes of scale. Practically all theories about every aspect of life — natural or human-made — break down when scaled in either direction. Let’s take a few examples:
Time: We can plan for the next few hours mentally straightforwardly, with some effort, and with the aid of a calendar for the next few days, but many of us struggle thinking about consequences for the next few years. Very few people can think about the implications for, say, the next ten years (many of them unsurprisingly are famed investors and that’s not an accident).
Money: As money scales, folks have trouble understanding what it is and what it can do as the nature of money itself changes with accumulation. As Marx notes:
The accumulation of capital, which originally appeared only as its quantiative extension, comes to fruition, as we have seen, through a progressive qualitative change in its composition. — Das Kapital (1867)
Lottery winners routinely get discombobulated when confronting their winnings, and most Americans have trouble grasping the extent of our national debt.

The nuance between the simple accumulation of capital and its qualitative effects is best illustrated in this supposed conversation between Fitzgerald and Hemingway in a 1920 Paris café:
Fitzgerald: “The rich are different from us.”
Hemingway: “Yes, they have more money.”
Crowds: People scale differently, too. It is not uncommon for a large collection of mediocre hires to come together and form a brilliant organizational unit. While individual and small group opinions are less interesting, Twitter, one of the largest opinion scaling experiments, has produced a sea change in thinking (#metoo, #BLM, ...) and massive information operations at once.
Physical Sciences: Nature is self-organized hierarchically, and it’s not a flaw that entirely new laws are needed to understand different scales (for e.g., Quantum Mechanics at a sub-atomic scale and General Relativity at a cosmological scale). In other words, every quantitative shift is accompanied by its own qualitative shifts.
“The whole becomes not only more than but very different from the sum of its parts.” — Anderson (1972), More is Different.
Even in an exact field like mathematics, singular limits exist, and known recurrences break down past a limit.

So, a natural question: What happens when we scale the number of parameters in a neural network to absurd levels? Are there “emergent” realities that cannot be explained by the component parts?
We already see some of this in VLP models like GPT-3 where the model is able to “solve” several unseen problems in natural language or other domains after seeing only a few examples (so-called “zero-shot” / “few-shot” generalization). But we don’t really understand how or why that happens. Studying this emergent reality should be the foremost preoccupation for anyone working on VLP models.
But What About Electric Shaver Brains?
Often discussions in AI wander into (sometimes unwarranted) comparisons with the human brain. One argument against parameter scaling is that human brains run on the power of an electric shaver, we could be wasting our time, effort, and energy running these VLP models on GPUs/TPUs. This argument is based on some flawed assumptions:
1. The human brain is a perfect piece of engineering and should be mimicked. This assumption is a trap for human thinking; indeed, few things are as marvelous to the human mind as the human brain. Francois Jacob, in his influential 1977 article, “Evolution and Tinkering” explains it best:
It is hard to realize that the living world as we know it is just one of the many possibilities; that its actual structure results from the history of the earth. … They represent, not a perfect product of engineering, but a patchwork of odd sets of pieced together when and where opportunities arose.
Opportunism reflects the “very nature of a historical process full of contingency”. In other words, we are a product of a variety of lotteries — physical, ecological, and historical. Changing the nature of these lotteries would lead to different outcomes and not necessarily provably better outcomes.
2. Low power != Fewer parameters. The ultra-low-power nature of human brains has more to do with its substrate than the number of connections. In fact, studies in evolutionary neurobiology and comparative neuroanatomy reveal strong correlations between body weight, brain weight, and the number of neurons.
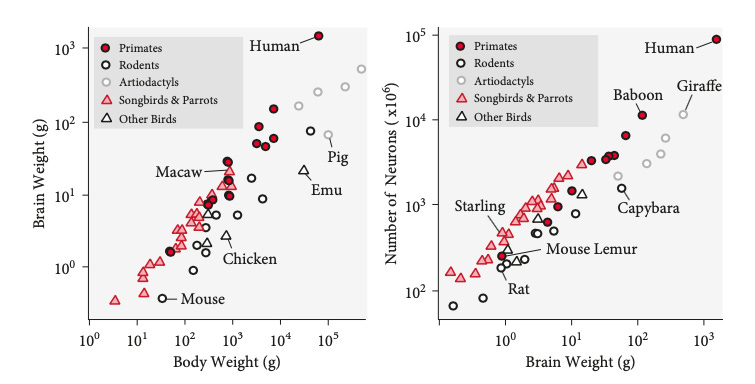
And it’s not that the brains of hominid species have remained static either. In fact, some researchers like Suzana Herculano-Houzel argue that Homo Sapiens have actually got a hardware upgrade over their ancestors primarily due to the invention of cooking, which provides a means to improve energy density in food, much like upgrading your power supply unit because you added extra GPUs.
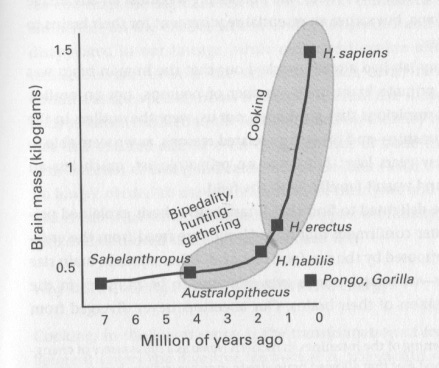
Perhaps, the future of AI will be very large parameter models running on ultra-low-power bioelectronics.
Aside: Pruning and Distillation of AI models are ways to reduce power consumption while approximating capabilities. Pruning removes inconsequential weights from a model, while distillation trains a seperate smaller model to mimic the outputs of a larger model in a teacher-student fashion. While these approaches have practical applications, they don’t create new capabilites over existing models.
Ride the Lottery!
The hardware lottery is a kind of resource lottery. Resource lotteries for innovation are not new in science and engineering, and if we look back, even nature has several examples of such lotteries. In fact, a general observation would be that resource lotteries are inevitable and we are also better served by focusing on answering interesting questions posed by current realities than an imagined future. In trying to create a uniform exploration of idea spaces divorced from economic/practical realities (to “avoid the hardware lottery”), we would be missing out on interesting research opportunities by shunting works simply because they don’t fit our current understanding of how the human brain works or is capable of.
In particular, one has to keep in mind that not all big models are alike, and Very Large Parameter models are uniquely interesting in that they add more capabilities to the model in ways we don’t understand today.

One way to look at AI modeling of today is to imagine ourselves in some Cambrian era with all sorts of brains proliferating from the most efficient to the least efficient. With competition for resources, the least efficient options will eventually get culled out, but in their wake, they may leave behind an understanding we would not achieve otherwise. Efficiency and capability of intelligent systems are two separate goals and any arguments in limiting the exploration of one goal for another comes from over-investing and extrapolating the limitations of current technologies.
Despite an electric shaver-like power efficiency, the human brain has limits that some of the Very Large Parameter models transcend (even if that’s unreliable today). A future I would like to live in is where human brains are augmented with capabilities that seem alien to me at this time of writing, via a second brain that does things so much differently than our wet brains.


Acknowledgments: Many thanks to Melanie Mitchell, Jen-Hao Yeh, and Cristian Strat for comments on early drafts of this.
Cite this article:
@misc{clarity:ride-hardware-lottery,
author = {Delip Rao},
title = {Ride the Hardware Lottery!},
howpublished = {\url{https://pagestlabs.com/clarity/ride-hardware-lottery}},
month = {November},
year = {2020}
}