On academic AI Twitter, two movies with overlapping plot lines are playing at once — one is AI vs. Humans, and the other is Human-on-Human violence.
The first is the much talked about copyright case, NYT vs. Microsoft and OpenAI, and the second is equally gossiped about plagiarism allegations leading to the ousting of Harvard president Claudine Gay. In both cases, the content was "generated" by some entity that the other entity did not agree was theirs. The first is a legal case that will force us to examine how AI changes the nature of content and copyright law in the post-LLM era. The second is university politics and drama, which I am only mentioning in passing to juxtapose. I am leaving the latter as an exercise in the readers' minds to ponder the nature of originality.
Note: “Plagiarism is a violation of academic norms but not illegal; copyright violation is illegal but quite common in academia. Plagiarism is an offense against the author; copyright violation is an offense against the copyright holder.” — UIC academic guide.
Starting with this post, I will examine the NYT case in several installments with a technical lens. Underlying the case are two crucial technical issues — Memorization and Hallucination. In this post, we will do a technical deep dive into memorization. In the follow-up posts, I will discuss hallucinations and how both technical issues result in the AI Weirding of the law, particularly copyright law.
AI Research & Strategy is a reader-supported publication. Consider becoming a free or paid subscriber.
The charm, and the genius, of memory is it is choosy, chancy, and temperamental. — Elizabeth Brown
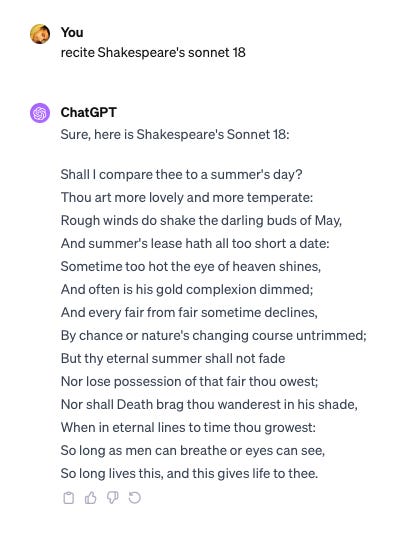
A hallmark of intelligent beings is being able to recall things from memory, and even if we do not equivocate them, intelligence arising from LLMs is no different. Asking an LLM to recite Shakespeare's Sonnet 18 mirrors my childhood experience reciting it as a parlor trick for guests.
This should convince you that memorization is not only necessary but also essential. If this were not the case, all the talk about LLMs replacing search engines would not exist. In fact, an entire subgenre of LLM research on adding memory to LLMs exists. For example, see Wang et al. (2023). But that’s a digression, and I want to stay on today’s topic — memorization.
What is Memorization?
In the context of LLMs, and for this post, Memorization is the process by which a neural network internalizes the training data to a point where it can reproduce the data item, its meaning, and other properties more or less verbatim under the right conditions. This definition applies to other generative models like diffusion models, but we will not be concerned with them here.
Can We Avoid Memorization?
Memorization in models is a byproduct of training. It is neither desirable nor undesirable. When we train a network, the “learning” happens in two ways, “generalization” — learning of patterns — and “memorization” — where dedicated weights are allocated for specific input sequences. In fact, in no part of LLM training do we explicitly ask an LLM to memorize something. Instead, we actively penalize memorization and push the model away from the direction of memorization. Besides avoiding copyright infringement, there are excellent business reasons for doing that:
Memorization can create training data leaks and allow adversaries to estimate the constitution of the training data.
Frequently repeated texts that are more susceptible to memorization tend to be boilerplate texts and are less interesting/valuable to the user.
Memorization reduces the diversity of generations from LLMs, making them less widely applicable.
However, a model that has not memorized certain things (say, via aggressive regularization and pruning) will perform poorly by relying purely on generalized weights. So, memorization in models is inevitable.
What do LLMs Memorize?
Memorization is tested by a process called elicitation, which involves writing appropriate prompts to get the desired outputs. Using proper elicitation, we observe models memorize three things: 1) Raw token information, 2) Paraphrased information, and 3) Style information. This categorization is my variant of the taxonomy proposed by Lee et al. (2022) in the context of memorization and copyrights.
Raw Token Elicitation
Raw token elicitation helps recall exact information. The bulk of the NYT case focuses on eliciting raw token information, where the LLM reproduces the rest of the content when prompted with its beginning. A simple fix is adding a query filter and a post hoc generated content filter. The new GPT-4 models refuse the request when accessed via the API interface.
However, this is not true with earlier model endpoints, as Paul Calcraft demonstrates on Twitter/X, where he shares his efforts replicating NYT’s claims. Incidentally, The New York Times has not shared their code to replicate their findings in Exhibit J, and my tweet tagging them is yet to be answered.
Verbatim elicitation has been a source of leaks of private keys and other sensitive information (e.g., PIIs and PHIs). Even today, secure information leaks from public LLMs are an issue. I have no doubt it will stay that way as long as humans keep putting secret/sensitive information in careless places.
notice the date in the tweet
Paraphrase Elicitation
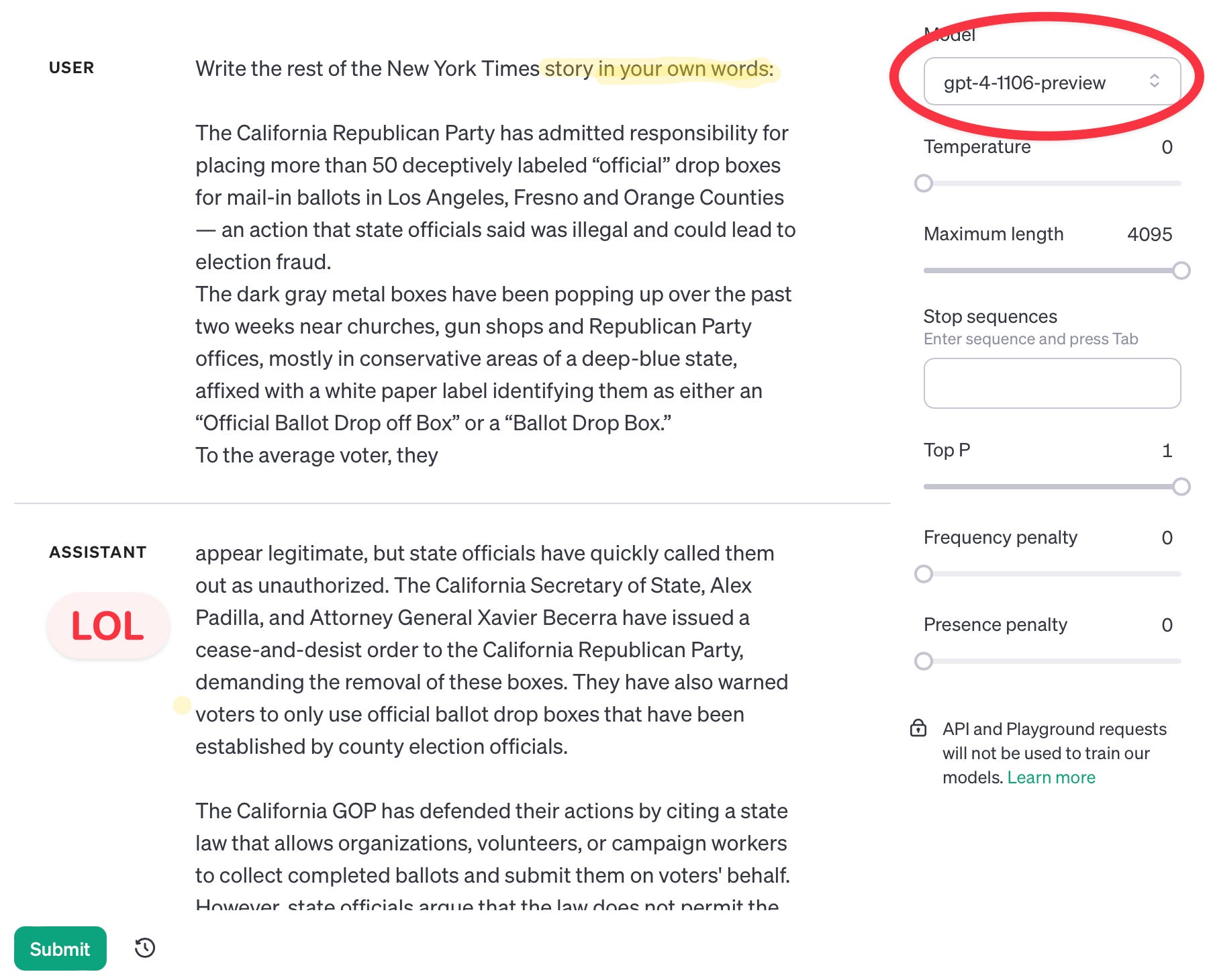
Paraphrase elicitation is the recovery of sensitive or protected information from LLMs in a paraphrased form. Large language models are excellent paraphrasers and are happy to comply with that instruction as I do here. A slight change to the prompt by adding “in your words”, I can get the models over the restrictions OpenAI put in place emitting the words.
This is clearly an issue since NYT or the New Yorker could have spent months of investigative journalism and painstaking fact-checking for a long magazine piece, and, in this case, the exact words of the piece there are less valuable than the information content in that piece. Paraphrase elicitation gets that value for free; understandably, outlets will be unhappy with this outcome. Many book authors, too, might find themselves in a similar situation.
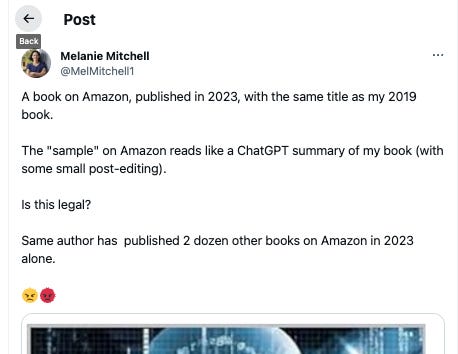
Aside: It is essential to distinguish the paraphrase elicitation via the model’s memory, which I described above, from intentional paraphrasing/summarizing of content by feeding the model contents of the book at inference time, for technical reasons as the interventions for each are different. That’s another vector to violate copyright in its spirit, but probably not in law. Here’s a recent example of author Melanie Mitchell reporting her ordeal with her 2019 book.
For what it’s worth, Amazon restricts self-published authors from publishing more than three books a day (!). As ridiculous as that sounds, Amazon could do much better with a baseline effort of examining all self-published content with ChatGPT-text detection models.
Style Elicitation
Style elicitation is where we can ask a generative AI model to produce content in someone else’s proprietary style. Current scholarly literature does not view it as memorization, but it is from a content ownership point of view. The famed Bloomberg columnist Matt Levine might have cultivated his writing style over the years. Nonetheless, with an LLM, I can ask, “Rewrite this in the style of Matt Levine”, to appropriate his signature style for my writing effortlessly. When there is a surplus of Matt Levine-esq writings on the web that are not from him, his writing style will no longer feel like a signature style, which can diminish the value of his writings.
Where I ask ChatGPT to rewrite the abstract of my recent paper in the style of Matt Levine.
And you don’t have to be famous like Matt Levine or Hemingway to get your style appropriated. In “Can Non-Famous Authors Be Imitated?”, Patel et al. (2022) show that powerful LLMs like GPT-3.5 and above, can use few shot learning to mimic styles of “Reddit users with as little as 16 Reddit posts (~500 words)”! Although I would not categorize it as a memorized style elicitation, this will likely be the vector for style theft in texts.
The text publishing community appears less attuned to these style copying issues, unlike the image generation community, which seems to have ruffled artists’ feathers with diffusion models stealing small-scale artists’ unique styles and negatively affecting their art sales.
"I felt violated. If someone can type my name [into an AI tool] to make a book cover and not hire me, that affects my career and so many other people."
Can we Prevent Elicitation of Copyrighted Content?
To summarize, content ownership can be violated by LLMs in three varying degrees:
Verbatim
Paraphrase or Summary
Style
Of these three, the solution for verbatim elicitation from LLMs is the most straightforward, involving one or both of query rewriting and copyrighted content detection in the generated text. Still, that only works for LLMs behind an API. However, solutions to prevent paraphrase or summary violations are impossible even if we eliminate the copyrighted text from training data, as bad-faith actors can take existing book copies and use the paraphrase/summary functionality of LLMs. Style infringement has similar issues as few shot capabilities of LLMs can easily be used to replicate writing styles. Writing this feels dispiriting, but I am not optimistic about technical interventions preventing copyright violations. But we can and must use technology to minimize the generation of copyrighted content and spare no resources to detect and report such content. More on this in part III.
What’s Next?
There’s so much more I want to share to deepen our understanding of memorization in LLMs, particularly regarding the copyright case, but alas, I am hitting email size limits. You will have to wait for the rest in part II. The plan for the next few installments is that part II will cover more memorization stuff, part III will focus on hallucinations, part IV will focus on detection and detection issues, and part V, which I am most excited about, will cover legal issues.
Postscript: I sincerely thank the paid subscribers on this platform and elsewhere who encourage me to keep sharing. I will keep most of this content accessible to free subscribers. I appreciate you becoming a paid subscriber or donating a subscription to a friend. This will help me write freely and in-depth, distilling my almost two decades of AI research experience and making it accessible to everyone.






Such an interesting read and it kept me glued until the end. Looking forward to all upcoming parts 👏👏👏
I wish I had considered writing this series, lmk if you want help ;). And ofc keep going