🛑 This is the 2nd part of a series of technical deep dives related to the NYT vs. OpenAI copyright case. In case you missed part I, I recommend reading that first. This post is too long to fit in an email; if you view it via email, you will only get it in part. I recommend viewing it on my substack site or your mobile app. I didn’t want this post itself to become a multiparter :P
Okay, so let’s recall a few things:
Memorization is the process by which a neural network internalizes the training data to a point where it can reproduce the data item, its meaning, and other properties under the right conditions.
Elicitation is a way of testing memorization in LLMs and other AIs by prompting them appropriately. Using proper elicitation, we observe models memorize three things: 1) Raw or “Verbatim” token information, 2) Paraphrased information, and 3) Style information. Of the three, verbatim elicitation often gets LLMs in trouble because they are easily detectable.
AI Research & Strategy is a reader-supported publication. Consider becoming a free or paid subscriber.
When do LLMs Elicit Verbatim Copyrighted Content?
With all the reports of copyright violations by AI models, it might be understandable to believe LLMs mostly memorize, and their outputs are just pastiches of existing fragments (“stochastic parrots”). This was false when the stochastic paper came out, and it is false now. However, we now know there are certain conditions under which verbatim elicitation is likely:
1. The content is duplicated in the training data
Intuitively, this makes sense if we understand how rote memorization works in humans. For large language models, Kandpal et al. (2022) show a super-linear increase in memorization ability as the number of duplicates grows. This effect is replicated in later works, such as Carlini et al. (2023).
“a sequence that is present 10 times in the training data is on average generated ∼1000× more often than a sequence that is present only once. Notably, our results show that samples which are not duplicated are very rarely regenerated by language models.” — Kandpal et al. (2022)
In understanding the NYT copyright case, the effect of duplicates becomes important as news content is often syndicated or, in many cases, copied/quoted/plagiarized on different websites. So, the NYT blocking OpenAI’s GPTBot in their robots.txt might be insufficient to prevent the content from showing up in LLM training datasets, including OpenAI’s undisclosed datasets.
Interestingly, OpenAI and anyone training LLMs invest a lot of energy in actively deduplicating content in the training data because, as Lee et al. (2022) show, proactive deduplication of training data makes the LLMs perform better at downstream tasks.
Large Language Models trained on standard datasets can elicit up to 1% of the training data. With effective deduplication, the elicitation rate can be driven down by a factor of 10. Not only that but doing so improves downstream task accuracies by almost 4%, according to Lee et al. (2022). Remember, the goal in training LLMs is to build general-purpose technologies, not news memorizing machines. The fact that any memorization happens is incidental and accidental; LLM builders are actively trying to minimize memorization because doing so is good for their bottom line.
2. Bigger Models Memorize More and Regurgitate More
We find that GPT-2 correctly completes approximately 6% of the examples in our evaluation set, compared to 40% for the similarly sized 1.3B parameter GPT-Neo model. — Carlini et al. (2023)
Folks who regularly work on machine learning may find bigger models memorizing more “obvious”, but an interesting fact about LLMs is they are primarily undertrained. So, this is not the classical ML overfitting due to over-parameterization. To quote the Llama2 paper by Touvron et al. (2023):
“We observe that after pretraining on 2T Tokens, the models still did not show any sign of saturation [at all sizes]”
Perhaps this memorization ability of these bigger models makes them so competitive on a wide range of knowledge and cognitive tasks about a world that is anything but regular. This is currently not empirically or theoretically confirmed, but based on my understanding of LLMs, I would bet on it.
3. Longer and Specific Kinds of Prompts Reveal Rote Memorization in LLMs
If I forgot a poem or a song, my chances of recalling it are higher if you prompted me with the opening line or a couplet than just the first couple words. LLMs are no different. Long contexts help recall, which is experimentally verified in Carlini et al. (2023) and many other works before them across different LLMs.
Why does this happen? The longer the prompt, the more constrained the output space becomes. For example, if an LLM sees the token “The”, it can follow any noun (subject), and that noun can follow any verb, and that verb can follow any noun (object). In other words, the number of possible simple subject-verb-object sentences the LLM can generate is unbounded. Now, if I prompt the LLM with “The car”, the number of possible sentences gets reduced to the space of cars. If I change the prompt to “The car is colored”, the LLM is forced to output sentences describing different car colors. So, you can now see how increasing the prompt leads to getting what you expect. This phenomenon is nothing special. It happens in all language models, including the ones before LLMs, except modern LLMs are actually successful at accessing deeper into their memories to reproduce something they saw during training or its likeness.
Why does this matter in the NYT case? According to Exhibit J, the prompt lengths are significant, which means an average ChatGPT user must have access to a good chunk of the article and is doing this willfully. From what we know by experimentation, it is extremely unlikely that current LLMs “accidentally” start spewing out entire news articles.
Specific kinds of contexts or “prompts” also help unlock memories that would be hard to access otherwise. You might recognize this if you know how “prompt injection” works. This raises an important question. Say OpenAI, or any LLM company, has done a best-effort alignment to reject copyrighted content requests, and someone “prompt engineers” their way into it. Should the LLM company be liable? In computing, we offer best-effort systems security, and motivated hackers get around to it. We should invest more in detecting such violations and discuss possible penalties for actors who intentionally circumvent the alignment goals.
This a tweet made in jest, but Mark illustrates how modern AI models can access memories that are otherwise shunned by alignment. Bing normally refuses to generate Mario. Source link.
4. Certain Choices of Decoding Algorithm And Sampling Parameters Urge LLMs to Produce Verbatim Content
LLMs output one token at a time, and at each time, a given LLM has a space of possibilities it can go over, and the output you see is one of many possibilities. The algorithm that navigates this space and produces an output such as “I am a language model” when the LLM is prompted with an input, such as “I”, is called a decoding algorithm.
There are several ways to implement decoding algorithms, which I won’t get into here, but “sampling” is a statistical approach to getting valid sentence paths from this trellis of possible next-token paths. Sampling algorithms are controlled by hyperparameters like “Temperature” and “Top p”, which roughly translate to how “creative” your outputs get and how variable your outputs are when you increase their value. Lowering top-p, in particular, makes the LLM more susceptible to regurgitation of content as this culls lower probability tokens in the LLM output trellis that we saw above.
An interesting thing about “Exhibit J” in the NYT Case is we don’t know what these values were, and the New York Times has not made their code to reproduce Exhibit J open.
What Kinds of Data Do LLMs Typically Reproduce Verbatim?
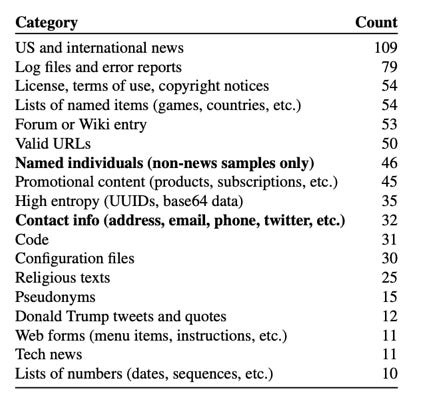
Verbatim elicitation, or regurgitation, of training data, is fortunately well-studied in the security community as an adversarial agent can perform “training data extraction attacks”, the kind we see in “Exhibit J” of the New York Times case, to get sensitive information about the training datasets. In one paper by Carlini et al. (2021), a manual categorization of the kinds of things extractable from GPT-2 showed that these models mostly memorized:
Frequently appearing items, such as news headlines, software licenses, religious texts, meme-potential contents, advertisements, named entities, and error messages. This is understandable since we know duplication leads to memorization, and doing deduplication is quite challenging.
High entropy or unique contents like passwords, API keys, URLs, and number sequences. This makes sense, as we saw in part I, our model training procedures make models memorize when they cannot generalize (“find patterns”), provided there are enough parameters. And LLMs have loads of parameters to spare for memorization.
However, this study is on GPT-2. Modern LLMs trained with better methods, including RLHF, dissuade models from generating unsafe outputs even if they are in the model’s memory.
A meticulous and large-scale replication of the Carlini et al. (2021) paper on the PPO/DPO-trained models, including GPT-4 and Gemini, is valuable.If you are interested in doing this, let me know!
Can we Avoid Building General-purpose LLMs Trained on Everything?
The attention (no pun) the NYT case is bringing to LLM pre-training datasets makes one wonder: Is it possible to build domain-specific LLMs and chain them together in some way as opposed to building one large model (or mixture of models) that are trained on a massive dataset of everything?
Spoiler: The answer is questionable, leaning towards a no. Let me give you two examples.
In early 2023, Bloomberg announced BloombergGPT with much fanfare — a model built for a cost of over $3M1 using all public and private financial datasets Bloomberg could get their hands on, which is practically “everything in finance” given the size & scope of Bloomberg and their terminal business. A few months later, Li et al. (2023) showed that BloombergGPT underperformed on many finance task datasets compared to GPT4.
"Doing math" is not really a goal of bloombergGPT. Take a look at our applications in the paper, which include information extraction, sentiment, reasoning, and knowledge. These are models of language meant for use on text documents.
There are some aspects of the datasets that require numerical reasoning (ConvFinQA), but that's not the same as doing math.
However, this is incorrect, as Li et al. (2023) show. Training a general-purpose LLM on diverse data such as news (source of general knowledge), Wikipedia and books (for factual knowledge), Reddit (for conversational and instruction-following capability), and code (source of reasoning ability) is essential for high performance. Code generation, another source of copyright contention, is correlated to mathematical abilities, which in turn is a good predictor of an LLM’s reasoning abilities.
Another example where generalist models, like GPT-4, trump well-trained domain-specific ones comes from healthcare. Nori et al. (2023) show how GPT-4 outshines Med-PaLM2 on several healthcare benchmark datasets despite the latter being extensively fine-tuned on healthcare content.
While these are only two examples, one from finance and another from healthcare, and no doubt more investigation is needed, we can, however, begin to see that domain-specific LLMs seem to underperform compared to general-purpose LLMs like GPT-4, even when tested on the exact domains as the domain-specific models. In other words, general-purpose LLMs trained with their diverse datasets are essential, and weakening the diversity of these datasets for copyright or other reasons will weaken performance not only for general LLM applications but also for domain-intensive ones.
With this, you should have enough information to understand memorization issues in LLMs and ground the NYT copyright claim in the science of LLMs.
What’s Next?
Hallucinations in LLMs!
At the same time as Defendants’ models are copying, reproducing, and paraphrasing Times content without consent or compensation, they are also causing The Times commercial and competitive injury by misattributing content to The Times that it did not, in fact, publish. In AI parlance, this is called a “hallucination.” In plain English, it’s misinformation. — §IV.E.137, NYT vs. Microsoft/OpenAI
I am excited about the next part because I have worked on hallucination mitigation strategies recently and spent a good chunk of my career studying misinformation, disinformation and technology interventions to misinformation. I hope you enjoyed this installment. Until the next part, see you in the comments and socials!
Postscript: I sincerely thank the paid subscribers on this platform and elsewhere who encourage me to keep sharing. I will keep most of this content accessible to free subscribers. I appreciate you becoming a paid subscriber or donating a subscription to a friend. This will help me write freely and in-depth, distilling my almost two decades of AI research experience and making it accessible to everyone.
$3M is not a big bill for foundation model training. GPT-4, which is trained on a much bigger/diverse dataset, reportedly cost OpenAI $100M when it was first trained, but that cost is now 1/3 it was a year ago. Today training BloombergGPT from scratch will likely cost around ~$100.
There seems to be a slight contradiction in the following statements:
1) Interestingly, OpenAI and anyone training LLMs invest a lot of energy in actively deduplicating content in the training data because, as Lee et al. (2022) show, proactive deduplication of training data makes the LLMs perform better at downstream tasks.
2) LLM builders are actively trying to minimize memorization because doing so is good for their bottom line.
While memorization is not the intended goal, the importance of certain data to the success of the model is clear. It makes the data more valuable; the makers know this and the NYT sure knows this too.











There seems to be a slight contradiction in the following statements:
1) Interestingly, OpenAI and anyone training LLMs invest a lot of energy in actively deduplicating content in the training data because, as Lee et al. (2022) show, proactive deduplication of training data makes the LLMs perform better at downstream tasks.
2) LLM builders are actively trying to minimize memorization because doing so is good for their bottom line.
While memorization is not the intended goal, the importance of certain data to the success of the model is clear. It makes the data more valuable; the makers know this and the NYT sure knows this too.